

в более явном виде, ибо
Такая аппроксимация выполняется и в более явном виде, ибо каждая

Следовательно, сеть строится и обучается так, чтобы заданное значение X =
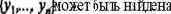


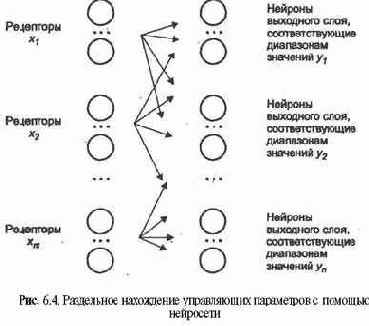
В результате выходной слой разбивается на области, каждая из которых закреплена за своим


Следует обратить внимание не только на высокую производительность такого рода самообучающихся систем в рабочем режиме, но и на их адаптивность, развитие, живучесть и т.д.